近日,全球最頂級大數據會議Strata Data Conference在京召開。Strata大會被《福布斯》雜志譽為“大數據運動的里程碑”,吸引了大數據、人工智能領域最具影響力的數據科學家與架構師參會。第四范式聯合創始人、首席研究科學家陳雨強受邀出席,并以“人工智能工業應用痛點及解決思路”為題,頒發主題演講。
陳雨強是世界級深度學習、遷移學習專家,曾在NIPS、AAAI、ACL、SIGKDD等頂會頒發論文,并獲APWeb2010 Best Paper Award,KDD Cup 2011名列第三,其學術工作被全球著名科技雜志MIT Technology Review報道。同時,陳雨強也是AI工業應用領軍人物,在百度鳳巢任職期間主持了世界首個商用的深度學習系統、在今日頭條期間主持了全新的信息流保舉與廣告系統的設計實現,目前擔任第四范式首席研究科學家,帶領團隊研究、轉化最領先的機器學習技術,著力打造人工智能平臺級產品”先知“。
以下內容按照陳雨強主題演講編寫,略有刪減。
大家好,我是來自于第四范式的陳雨強,目前主要負責人工智能算法研發及應用的相關工作。非常高興與大家分享人工智能在工業界應用的一些痛點、以及相應的解決思路。
工業大數據需要高VC維
人工智能是一個非常炙手可熱的名詞,且已經成功應用在語音、圖像等諸多領域。但是,現在人工智能有沒有達到可以簡單落地的狀態呢?工業界的人工智能需要什么技術呢?帶著這些問題開始我們的思考。
首先,我們先探討一下工業界人工智能需要一個什么樣的系統?人工智能的興起是由于數據量變大、性能提升以及并行計算技術發展共同產生的結果。所以,工業界的問題都是非常復雜的。因此,我們需要一個可擴展系統,不但在吞吐與計算能力上可擴展,還需要隨著數據量與用戶的增多在智能水平上可擴展。怎么實現一個可擴展系統呢?其實很重要的一點是工業界需要高VC維的模型,去解決智能可擴展性的問題。怎么獲得一個高VC維的模型呢?大家都知道,機器學習=數據+特征+模型。如果數據在給定的情況下,我們就需要在特征和模型兩個方面進行優化。
特征共分兩種,一種叫宏不雅觀特征,比喻說年齡、收入,,或是買過多少本書,看過多少部電影。別的一種是微不雅觀特征,指的是相比細粒度的特征,你具體看過哪幾本書,或者具體看過哪幾部電影。每一部電影,每一本書,每一個人,都是差別的特征。書有幾百萬本,電影有幾百萬部,所以這樣的特征量非常大。
模型可分為兩類,一個是簡單模型,好比說線性模型。還有一種是復雜模型,好比非線性模型。
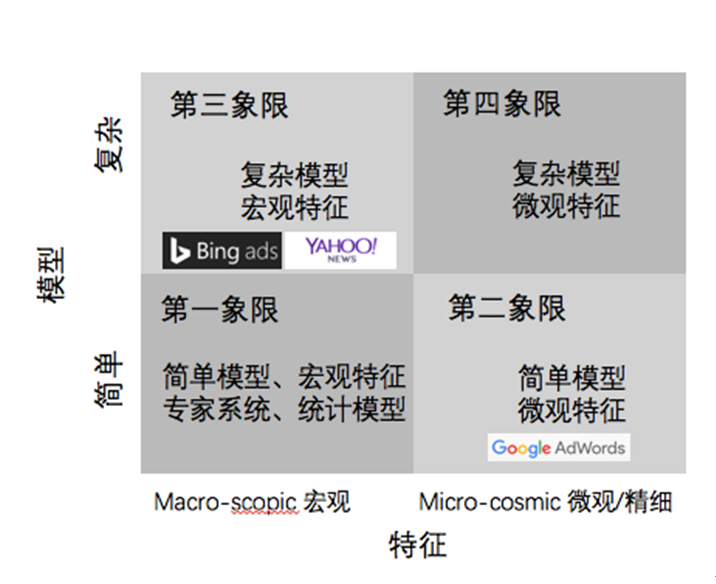
這樣就把人工智能分為了四個象限。如上圖,左下角是第一象限,使用宏不雅觀特征簡單模型解決問題。這種模型在工業界應用非常少,因為它特征數少,模型又簡單,VC維就是低的,不能解決非常復雜的問題。右下角的第二象限是簡單模型加上微不雅觀特征,最有名的就是大家熟知的谷歌Adwords,用線性模型加上千億特征做出了世界頂尖的廣告點擊率預估系統。左上角的第三象限是復雜模型加宏不雅觀特征,也有諸多知名公司做出了非常好的效果,例如Bing廣告和Yahoo,經典的COEC+復雜模型在這個象限內是一個慣用手段。最后是第四象限,利用復雜模型加上微不雅觀特征,由于模型空間太大,如何計算以及解決過擬合都是研究的熱點。
剛才說沿著模型和特征兩條路走,那如何沿著模型做更高維度的機器學習呢?研究模型主要是在學術界,大部分的工作是來自于ICML、NIPS、ICLR這樣的會議,非線性有三把寶劍別離是Kernel、Boosting、Neural Network。Kernel在十年前非常火,給當時風靡世界的算法SVM提供了非線性能力。Boosting中應用最廣泛的當屬GBDT,很多問題都能被很好地解決。Neural Network在很多領域也有非常成功的應用。工業界優化模型的方法總結起來有以下幾點。首先,基于過去的數據進行思考得到一個假設,然后將假設的數學建模抽象成參數加入,用數據去擬合新加入的參數,最后用另一部分數據驗證模型的準確性。這里舉一個開普勒沿模型這條路發現開普勒三定律的例子。在中世紀的時候,第谷把本身的頭綁在望遠鏡上堅持不雅觀察了30年夜空,將各個行星的運動軌跡都記錄下來。基于這些數據,開普勒不停的進行假設,最后假設行星的運動軌道是橢圓的,用橢圓的方程去擬合他的數據,發現擬合的非常好,便得到了一個新的模型:開普勒第必然律。這就是一個典型的沿著模型走的思路,通過不雅觀測數據,科學家獲得一個假設,這個假設就是一個模型,然后用數據擬合這個模型的參數,最終在新的數據上驗證模型是否正確,這是沿著模型走的一條路。
